

Sur Google, vous connaissez tous le Google Graph. Vous savez, l’encart que vous propose Google lorsque vous faites une requête générique.
Cela fonctionne sur des noms communs (je vous invite à taper "paté" sur notre moteur de recherche préféré. Ca ne sert à rien mais c’est marrant) mais aussi et surtout sur les noms propres.

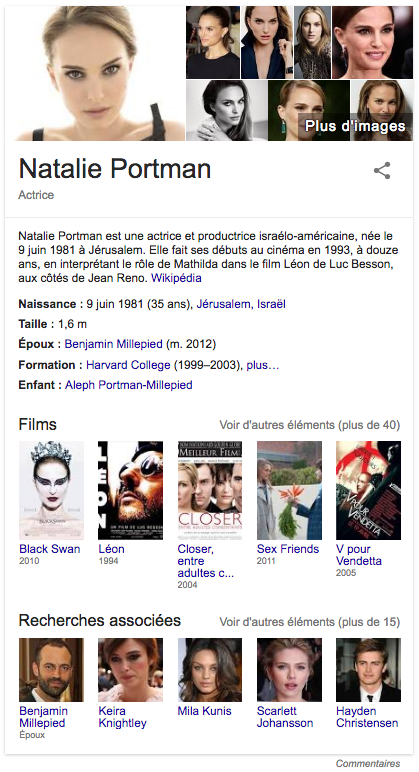
D’un point de vue utilisateur, c’est surtout utile pour retrouver des informations rapidement sur une personne, un film, une personne morale etc.
Et si on se place du côté de l’entité ça donne une belle reconnaissance et des informations très utile pour quiconque souhaite des informations sur vous.
Mais pour une fois, plaçons-nous du côté de Google. Qu’elles sont ses motivations ? À quoi peut bien servir réellement ce Graph ? Et surtout, comment l’alimente-t-il ?
La première chose qui vient en tête (et notamment à celle des anti-Google) serait de dire que Google se sert de ce Graph pour proposer les informations directement sur son site ; que Google pompe le contenu des sites pour s’accaparer tout le trafic sur internet et ne rien laisser aux autres…
C’est en partie vrai, qui a besoin d’aller sur Allociné quand on peut tout savoir sur un film ou un acteur directement sur Google ? Mais d’un autre côté, peut-on jeter la pierre à Google ? Que feraient les sites internet sans lui ? Tout se jouerait sur la notoriété et internet ne serait pas ce qu’il est… (et ne me parlait pas des concurrents car Bing ou Qwant feraient/feront la même chose s’ils étaient à la place de Google)
Et enfin, vous pouvez me traiter de pro-Google mais au final, est-ce que les informations du Graph n’obligent-elles pas aux sites internet à élever leur niveau rédactionnel et de les forcer à proposer un contenu de meilleur qualité ?
Une fois cette première proposition qui était sur toutes les lèvres dite, essayons de voir plus loin. Quel est l’intérêt de Google, qu’elles sont ses motivations réelles et comment alimente-t-il ses Graphs ?
Comme pour tout, il y a deux niveaux de lecture aux actions qu’entreprend Google : La justification officielle et celle bien plus officieuse…
Officiellement, Google tente de faciliter l’accès aux informations aux internautes. Rendre le savoir accessible à tous. Et qu’on aime ou pas Google, il faut savoir le dire : merci Google que ce soit avec ton moteur de recherche ou avec ton opération pour rendre internet accessible à tous, le travail est bien fait.
Imaginez le nombre de "Monsieur Jesaistout" que Google nous a permis de coincer !!
Officieusement, Google est à la recherche d’informations pour nourrir/gaver ses robots afin de développer le machine learning et créer une intelligence artificielle qui réduira l’humanité en esclavage (pour les fans de Matrix) ou tout simplement la faire disparaître (pour les pro Terminator).
Plus sérieusement, le machine learning (car nous n’en sommes que là pour l’instant) n’est pas si terrible, bien au contraire. L’idée derrière ce terme compliqué, est de faire en sorte que les robots apprennent par la répétition. Pour l’application qui nous intéresse, le robot Search va apprendre des milliards de requêtes des internautes pour en sortir des patterns qui se répètent. Et ainsi, pouvoir proposer aux internautes des résultats encore plus précis et personnalisés.
Aujourd’hui, Google s’en sert déjà derrière le fameux facteur de ranking « Rank brain ». Mais pas seulement.
N’oublions pas le sujet de ce billet ! Il n’est pas question de Rank Brain ici mais bien des Google Graphs. Personnellement, je pense que Google, grâce au machine learning, regroupe toutes les informations liées à une entité dans une table (une table de donnée, pas celles d’Ikea). Plus précisément, je pense que c’est l’inverse (du moins au départ). Google regroupe des informations qui se recoupent et crée, une fois qu’il y a suffisamment de matière, une entité.
Une fois cette entité créée, Google propose dans ses résultats le Graph associé, qu’il enrichi peu à peu par la suite.
Pour enrichir ses informations, Google se sert de 3 choses : les rich snippets (ou micro-données) ; le netlinking (tous les liens pointent vers un site/entité) et une fois l’entité créée, par tout ce qui fait mention de cette entité.
Et de ce fait, est-ce qu’on peut affirmer, par extrapolation, que la notoriété d’un site ne passe plus uniquement par les liens qui pointent vers lui mais par n’importe quelle phrase qui mentionne le nom du site ou de son entité ?
N’est-ce pas là, la fin de notre bon vieux Page Rank que Google nous promet depuis plusieurs années maintenant ?